Por: Bernardo Mejía Arango.
PARA QUÉ SIRVE EL ANÁLISIS DE ADN DEL CROMOSMA Y?
PARA QUÉ SIRVE EL ANÁLISIS DE ADN DEL CROMOSMA Y?
Cuando decidí pagar para que un laboratorio de los
Estados Unidos realizara un análisis del ADN del cromosoma Y a partir de una muestra mía, tenía muy claro que quería seguir en
términos genealógicos mi línea paterna y corroborar tanto la parte documental que me decía que mis ancestros patrilineales, los Messia más próximos venían
de España, de Villacastín en Segovia,
en la comunidad autónoma de Castilla y
León.
Quise ir más allá de lo que dicen los documentos, quise
saber en términos de cientos de miles de años, de donde venían mis genes, los
contenidos en el cromosoma Y (En su región no recombinante que equivale al 95%) que lleva mi hijo y que heredó de mi, que yo llevo y que heredé de mi padre, mi padre de mi
abuelo y así sucesivamente hasta donde fuera posible.
Y es que este es el fundamento de la prueba que analiza el cromosma Y: esta prueba traza
la línea paterna, sin influencia de las madres. Este principio de basa en que los varones tenemos dos cromosomas sexuales:
X y Y. Las mujeres tienen XX como sus dos cromosomas sexuales. En otros
términos, las mujeres no transmiten el cromosoma Y puesto que no lo tienen, los
varones si.
Y esto se explica porque en el proceso de formación de los espermatozoides
(Espermatogénesis), la carga genómica debe reducirse de 46 a 23 cromosomas. En este sentido, el varón
aporta solo la mitad de su genoma y
por lo tanto pueden producir
espermatozoides con cromosoma X o espermatozoides con cromosma Y. La mujer
aporta al proceso de fecundación un óvulo que tiene la mitad de la carga
cromosómica (23 cromosomas) de esos 23, un cromosoma que siempre será X.
Cuando el espermatozoide fecunda un óvulo, puede aportar un
cromosoma X o un cromosma Y. Si el
espermatozoide aporta X, el nuevo ser será una mujer. Si aporta Y, el
nuevo ser será un hombre. Ese hombre que nace tendrá el mismo proceso y podrá transmitir
el cromosma Y (Su región no recombinante que equivale al 95%) de la misma manera que él lo recibió de su padre.
El cromosma Y
representa solamente el 2% del genoma humano, es uno de los cromosomas más pequeños, con un tamaño aproximado de 60
Mb (En genética 1 Mb es igual a un millón de pares de bases). El 95% del cromosoma Y no recombina (No intercambia material genético con
el cromosoma X) por lo que se transmite de forma intacta de padre a hijo; esto es
lo que hace que a través del cromosoma Y puedan estudiarse linajes paternos.
http://www.genealogia.org.mx/molecular/index.php?option=com_content&task=vi
 |
| Figura 1. El cromosma Y se hereda de padres a hijos solo en forma patrilineal, es decir solo entre varones. Es por eso que a través de los estudios del ADN del cromosma y (ADN-Y) se puede averiguar nuestra ancestría en términos genéticos, varios, muchos cientos de miles de años en sentido restrospectivo en nuestro árbol genealógico (En términos genéticos). |
- Los cromosomas Y vienen “marcados” con su haplogrupo y por lo tanto se puede hacer un rastreo ancestral por 25 generaciones en forma patrilineal.
- A través de su análisis se puede establecer una ruta de migración hacia atrás, por miles de años.
- Los resultados de nuestro análisis se pueden enfrentar con bases de datos de la misma compañía que los produjo o con bases de datos de otras compañías. De esta manera se pueden encontrar nuestros familiares en términos de ADN del cromosma Y.
Las técnicas para
efectuar los análisis del ADN del cromosma Y se basan en estudios de sitios muy específicos del cromosma Y, son los STRs (Microsatélites o secuencias de ADN en las que un fragmento del mismo, cuyo tamaño va de dos hasta seis pares de bases, se repite de manera consecutiva. También se llama repetición en tándem) y los SNPs (Polimorfismo único de un solo nucleótido, que es una variación en la secuencia de ADN que afecta solo un base: adenina o timina o citosina o guanina) de una de las secuencias del genoma); esto mismo se hace en técnicas para estudiar el ADN de los cromosomas autosómicos o ADN autosómico. Los marcadores STR son lugares en los
que el código genético tiene
un número variable de partes repetidas.
Estos valores pueden cambiar pero
lo hacen lentamente entre generaciones. Los parientes genéticos se pueden medir
en términos de DISTANCIA GENÉTICA,
conjunto de palabras que pueden definirse así:
- Es el número de mutaciones entre dos conjuntos de resultados. Si la distancia genética es cero, esto quiere decir que la coincidencia es exacta. La distancia puede ir aumentando de acuerdo con la cantidad de diferencias, por ejemplo puede ser 1, ó 2, etc. Esto se aplica para resultados tanto del ADN del cromosoma Y como del ADN mitocondrial.
- La distancia genética es la longitud del segmento en la unidad de medida denominada centimorgans.
En los resultados que envía el laboratorio, hay una sección donde se pueden visualizar lo que ellos llaman "matches" o "partidos" que no es más que personas que comparten en forma exacta o parcial nuestro ADN del cromosma Y.
El cromosoma Y posee funciones biológicas importantes
relacionadas básicamente con la función testicular y la fertilidad masculina.
El cromosma Y tiene tres
regiones:
- Dos de ellas son pseudoautosómicas y se denominan así porque en el proceso de meiosis (generación de una célula que tiene la mitad de los cromosmas, como es el caso de los espermatozoides o los óvulos) intercambian material genético con el cromosma Y por lo que en material de herencia genética estas dos regiones se comportan como autosomas: es el 5% del cromosoma.
- Una región no recombinante, que es específica del cromosma Y, como no intercambia material genético se transmite integra de padre a hijo: es el 95% del cromosma
 |
| Figura 2. Certificado remitido por Family Tree DNA al suscrito, en donde consta que a partir de mi muestra de hisopado bucal, hicieron el rastreo de 67 alelos (Sitios en el cromosma donde están mis STRs o SNP) que componen mi haplotipo. Es decir consta que analizaron un panel de 67 marcadores de mi cromosma Y |
Cuando la compañía que
hace los análisis de ADN del cromosma Y remite los resultados a quien
compró la prueba, anexa un certificado como el que está en figura No. 2. En este caso, el certificado
está dirigido al suscrito y me está informando que examinaron los 67 marcadores o alelos
ubicados en 67 loci (lugar que ocupa en el cromosma). Este es mi haplotipo, y es el
que busco cuando en las bases de datos enfrento mi información con la que allí
reposa, tratando de encontrar coincidentes ("pares" o matches", es decir personas con mi mismo
haplotipo (Total o parcial).
Un marcador tiene una ubicación física (Locus) en un
cromosma, El término se usa con frecuencia coloquialmente en la genealogía
genética para referirse a una repetición en tándem (STR). Por ejemplo, la
prueba que se muestra en el certificado en “Y-DNA67”, es un panel de 67
marcadores.
En cada alelo hay un microsatélite con secuencias
constituidas por repetición en tándem (STR-Y). En cada alelo o marcador solo hay
una copia, esto debido a que los marcadores se encuentran en una región no
recombinante del cromosoma y que es específica de este y del cual solo hay una
copia por individuo.
Estos marcadores se encuentran en una región
no recombinante del cromosma, lo que hace que todas las secuencias
ubicada en esta zona del cromosoma se hereden en bloque.
Al conjunto de alelos
obtenidos tras el análisis de una serie de marcadores de este tipo, se denomina haplotipo.
Es necesario desambigüar los términos haplogrupo y haplotipo, términos usados indiscriminadamente. El Haplogrupo es R y los haplotipos surgen a partir de allí. En lo personal, creo que es mejor hablar de clado (Que sería el haplogrupo) y de subclados (Que serían los haplotipos). Un poco más adelante se verá los de los clados y los subclados, entonces quedará más fácil entenderlo (Figura 4)
Gracias al avance sufrido en las técnicas de análisis
genético en los últimos años, el estudio del ADN del cromosoma Y ha revelado una gran
cantidad de polimorfismos de gran utilidad en:
- Estudios del origen y evolución de las poblaciones
- Estudios de paternidad
- En medicina forense para identificaciones humanas y en la resolución de casos de criminalística
DNA MATCHING PARA LA HISTORIA FAMILIAR
Mediante los análisis de ADN del cromosma Y (ADN-Y) se pueden encontrar los "primos" genéticos (Yo les llamaría "parientes", término más entendible para nosotros en nuestra jerga) a lo largo de la línea
paterna. Hay formas de enfrentar la información con bases de datos existentes
de personas que ya se han hecho la prueba. Desde luego que se pueden establecer
las zonas geográficas de donde provienen.
ORIGENES ANCESTRALES
Nuestro ADN del cromoma Y marca el camino de nuestros
antepasados paternos, hasta nuestros ancestros en Africa. Los antepasados
llevaron el ADN en sus viajes. La distribución geográfica actual de
nuestras líneas nos muestra ese camino.
Esta información viene de los científicos que estudian la historia de as
poblaciones a través de la geografía y el tiempo, utilizando el análisis del ADN del cromosoma
Y.
Ellos usan tanto las frecuencias de cada rama en las
poblaciones modernas y muestras de los antiguos cementerios. Esto se remonta en
cientos, miles o incluso decenas de
miles de años. Mi rama en el árbol
donde están mis antepasados paternos están determinadas en estudios
previos hechos por los científicos.
Mi haplotipo me ubica en una de esas ramas. El haplogrupo
es básicamente el principal resultado de
mi análisis del ADN del cromosoma Y a
partir de mis muestras. Recordemos que en evolución molecular, un haplogrupo es un grupo grande haplotipos o series de alelos en lugares específicos del cromosma) y que los haplotipo, en genética, es una combinación de alelos en diferentes sitios o loci de un cromosoma, que son transmitidos juntos.
Los resultados de los análisis de muestras del suscrito Bernardo Mejía Arango, llevadas a cabo por la compañía Family Tre DNA (Gene by Gene Ltd.) de los Estados Unidos, dice que mi haplogrupo obtenido a partir del análisis del ADN del cromosma Y (ADN-Y) es el R y mi haplotipo es el R-M269.
Así que este haplogrupo R muestra el camino de mis antepasados paternos hasta África. Mis antepasados llevaron a su línea
Y-DNA en sus viajes. La geografía
actual de su línea muestra el camino de este viaje. Uno puede aprender sobre los
aspectos básicos de la rama de nuestra línea paterna en el árbol de la evolución de los haplotipos.
 |
Figura 3. HAPLOGRUPOS DEL ADN DEL CROMOSOMA Y HUMANO
|
 |
Figura 4. Árbol simplificado de haplogrupos del cromosma Y. En genealogía genética a este tipo de árbol donde se ubican los haplogrupos se denominan cladograma. Un clado (Del griego κλάδος [clados], «rama») es como se denomina en biología a cada una de las ramificaciones de un árbol filogenético (https://es.wikipedia.org/wiki/Clado) Cada haplotipo es un clado y los subhaplotipos son subclados. Así que R1b que es mi haplotipo es un subclado del haplogrupo R.
https://www.wikitree.com/wiki/Space:Major_Y-DNA_and_mtDNA_Haplogroups. La imagen está en .wikitree.com y es cortesía de JD. MacDonald. WorldHaplogroupsMaps.pdf
|
Esta información proviene de los científicos que estudian la historia de las poblaciones a través de la geografía y a través del tiempo utilizando los análisis de ADN del cromosoma Y. Ellos utilizan para construir el árbol filogenético, los resultados de las poblaciones modernas pero igualmente pueden recurrir a muestras de los antiguos cementerios.
Con
éstos, son capaces de decirnos mucho acerca de la historia de cada rama. Esto se remonta a cientos, miles o
incluso decenas de miles de años. Mi rama en el árbol dónde están mis antepasados paternos están presentes hoy e informa sobre las posibles rutas de migración.
HAPLOGRUPO R-M269
El haplogrupo R-M269 (Subclado de R1b, a su vez subclado de R)), también conocido como R1b1a1a2, es un subclado del haplogrupo R1b (También denominado M343, inicialmente llamado Hg1 y Eu18)
https://es.wikipedia.org/wiki/Haplogrupo_R1b_del_cromosoma_Y
QUE SON LOS CLADOS
Un clado (del griego κλάδος [clados], «rama») es como se
denomina en la biología a cada una de las ramificaciones que se obtiene
después de hacer un único corte en el árbol filogenético. Empieza con un antepasado común y consta
de todas sus descendientes, que
forman una única rama en el árbol de la vida. El antepasado común puede ser un individuo,
una población, una especie, no
importa si extinto o existente, y así hasta llegar a un reino. También lo sinonimiza con un "grupo monofilogenético".
Dupuis, Claude (1984). «Willi Hennig's impact on taxonomic thought». Annual Review of Ecology and Systematics 15: 1-24
JS Huxley (1957) The three types of evolutionary process. Nature 180:454-455
 |
|
Revisando el resultado del análisis de mi ADN del cromosma Y, el reporte dice que el haplogrupo es el Rb1 (M269). Lo veo hacia el extremo superior del cladograma publicado por Eupedia el cual es de 2017. La compañía Family Tree DNA (Gene by Gene Ltd.) no hizo el estudio en términos de haplogrupos más recientes. Si se mira la figura 5, el reporte hecho por el laboratorio que hizo los análisis, solamente llega hasta la mitad del cladograma (Dato encerrado con un círculo rojo). Al averiguara al respecto, si quiero análisis más extensos, debo pagar por ellos (De hecho este tipo de análisis es un negocio) Igualmente, no encontré reportes de frecuencia del haplogrupo en América.
|
A la evolución le es concomitante la divergencia, de manera que, dadas dos especies cualesquiera, derivan de un antepasado
común más o menos remoto en el tiempo. Desde que se aplica esta consideración,
el ideal de la clasificación biológica es agrupar a las especies por su grado de
parentesco. Se les ubica más cerca a las del antepasado común más próximo.
En el estudio del parentesco de las especies en el tiempo
(linajes), el análisis filogenético, se realiza ahora mediante métodos muy eficaces, como la comparación directa
de secuencias de ADN y otras
fuentes de evidencia genética: ultraestructura ,
paleontología, bioquímica. En los árboles filogenéticos se resume lo que se sabe de la historia
evolutiva.
En Wikipedia se encuentra esta información: es un subclado del haplogrupo humano R1B fue previamente conocido como:
- R1b1a2: desde 2003 hasta 2005
- R1b1c: desde 2005 hasta 2008
- R1b1b2: desde 2008 hasta 2011
https://en.wikipedia.org/wiki/Haplogroup_R-M269
En lo personal y después de revisar sobre el tema, creo que hay una mala información. Creo más
bien que R1b1a2, r1b1b2 y R1b1c son subclados de RB1 y no diferentes nombres en diferentes años.
En lo personal y después de revisar sobre el tema, creo que hay una mala información. Creo más
bien que R1b1a2, r1b1b2 y R1b1c son subclados de RB1 y no diferentes nombres en diferentes años.
El
haplogrupo R1b se define por la presencia del polimorfismo de nucleótido
simple M343, el cual fue descubierto en 2004.
De acuerdo con el cladograma, entonces R1b1a1a2 se define por la presencia del polimorfismo de nucleótido simple M-269
Es de particular interés para la historia genética de Europa occidental. Se define por la presencia de SNP marcador M269
R-M269 es el haplogrupo más común en Europa, y su frecuencia se incrementa a medida que se avanza hacia el oeste de Europa. Su prevalencia en Polonia es de 22.7% en comparación con Gales que tiene el 92.3%. En 2010 se calculaba que 110 millones de hombres europeos que tenían el haplogrupo
Es probable que este haplogrupo se formara en el neolítico europeo y sus subclados se pueden utilizar para rastrear la ola de expansión neolítica.
La edad de la mutación se calcula entre 4.000 y 10.000 años, por lo que se deduce que el haplogrupo se formara en el neolítico.
https://en.wikipedia.org/wiki/Haplogroup_R-M269
 |
| Figura 6. Este es el mapa de migración remitido junto con los resultados de los análisis del ADN de mi cromosma Y. El haplogrupo R se formó a partir del haplogrupo P, este a su vez a partir del haplogrupo F y este a partir de C, en Africa. En los mismos resultados me indican que soy específicamente R1b. Este mapa, remitido junto con los resultados de los análisis de mi ADN del cromosma Y, está más que desactualizado; no tengo claro porqué el haplogrupo termina en la región de Europa que hoy corresponde a Francia, debió llevarse hasta la península Ibérica. De la misma manera no muestra nada en América donde nuestros genes llevan más de 400 años. En realidad creo que el mapa remitido con los resultados es muy sencillo, muy básico. Se encuentra mucha más información sobre análisis del ADN del cromosma Y en internet y sobre los clados o ramificaciones. |
En la información remitida junto con los resultados de los análisis, hay un segundo mapa, más completo, en el cual se ve la ruta de migración del haplotipo Rb1, hasta la península ibérica. De allí debe haber pasado a Colombia (O a lo que era en ese entonces: la Nueva Granada) con los conquistadores españoles.

Figura 7. Mapa de migración de los haplotipos del cromosma Y, elaborado por Family Tree DNA. en la parte inferior derecha dice copyright 2006, es decir hace 11 años. No es claro porqué me remitieron con los resultados de los análisis, un mapa de migración tan simple como el que se muestra en la imagen anterior (Figura 6), la ruta ni siquiera termina en la península ibérica, desde donde vinieron nuestros genes a lo que hoy es Colombia. Igualmente, este (Figura 7) mapa fue elaborado hace 11 años, tiempo en el cual ha habido muchísima investigación en el tema y se ha ampliado bastante el cladograma. Creo que hay un afán financiero en esta compañía y una falta de seriedad en la emisión de sus resultados.
Y es que de acuerdo con una publicación de la Sociedad internacional de Genealogía Genética (ISOGG) en 2016, cuando se toma una prueba estándar de ADN del cromosoma Y con compañías como Family Tree DNA, a usted le dan un haplogrupo base R1b1a2 (R-M269). Es entonces necesario análisis adicionales de SNP para confirmar a cual subclado de R1b usted pertenece. Dice la publicación que a veces es posible obtener un resultado predictivo a partir de una prueba de 67 marcadores STR-Y, Si la persona tiene concordancias (personas con resultados similares a una corta distancia genética), entonces se puede ordenar una prueba simple de ADN, de lo contrario hay que ordenar una prueba full de SNP
"When you take a standard Y-chromosome DNA test with
a company such as Family
Tree DNA you
will be given a base haplogroup assignment such as R1b1a2 (R-M269). It is
necessary to order additional SNP testing
to confirm which subclade of
R1b you belong to. It is sometimes possible to predict the R1b subclade from a
67-marker Y-STR haplotype.
If the participant has close matches at 67 markers the prediction can sometimes
be informed by the SNP status of his matches. If the subclade can be predicted
with reasonable confidence then single SNP testing can be ordered from Family
Tree DNA's à la carte SNP menu. Otherwise it is necessary to order a full SNP test for
confirmation of your SNP status. SNP status can also be confirmed with the 23andMe test
though this incorporates a much smaller range of Y-SNPs and will not provide
such a detailed haplogroup assignment."
ORIGEN Y DISPERSION DEL HAPLOGRUPO Rb1
R1b es un subclado dentro de la "macro-haplogrupo" "Haplogrupo" K (K-M9), que es una de las agrupaciones predominantes de todo el resto de líneas masculinas humanos fuera de África. K se cree que se originó en Asia (como es el caso con un haplogrupo incluso antes ancestral, F, (F-M89). en un "rápido proceso de diversificación de K-M256 probablemente ocurrió en el sudeste de Asia, con expansiones hacia el oeste posteriores de los ancestros de haplogrupos R y Q ".
https://en.wikipedia.org/wiki/Haplogroup_R1b (Referncia 2)
https://en.wikipedia.org/wiki/Haplogroup_R1b
QUÉ DICEN LOS RESULTADOS (Emitidos por Family Tree DNA)

Figura 8. De acuerdo con el informe remitido al suscrito por Family Tree DNA (Gene by GeneLtd.) el haplogrupo RM269 se encuentra en: Europa, norte de Africa, Medio Oriente, sur de Asia, Asia central y norte de Asia. No enviaron reportes de frecuencia en América y parece, de acuerdo con las figuras de frecuencia, no hay R-M269 en el pacífico sur ni en el centro-sur de Africa.

Figura 9. A partir del mapa de frecuencias remitido por Family Tree DNA (Gene by Gene Ltd.) las siguientes son las frecuencias del haplogrupo R-M269 en las seis regiones del mundo donde se reporta: Europa: 45.43%; norte de Africa: 6.11%; Medio Oriente: 20.56%; norte de Asia: 7.66%; sur de Asia: 40.51%; Asia central: 31.44%
El punto de origen de R1b se cree que está en Eurasia, muy probablemente en Asia Occidental T. Karafet et al. (2008, ver referencia 7 en la cita bibliográfica) estimaron la edad de R1, el padre de R1b, como 18.500 años antes del presente.
Las primeras investigaciones sobre los orígenes de R1b se centraron en Europa. En 2000, Ornella Semino y sus colegas (ver referencia 8 en la cita bibliográfica) argumentaron que R1b había estado en Europa antes del final de la edad de hielo, y se había extendido hacia el norte desde un refugio Ibérica después del último glacial (Ocurrió hace unos 20.000 años). Las estimaciones de edad de R1b en Europa han disminuido de manera constante en los estudios más recientes, al menos en relación con la mayoría de R1b, con estudios más recientes que sugieren una edad neolítica o menos. (ver referencias 6, 9, 10, 11 en la cita bibliográfica) Por otro lado, Morelli et al. recientemente (en 2010, referencia 12) han intentado defender un origen paleolítico de R1b1b2.
Algo muy importante que encontré en la revisión (2015), dice que el investigador Michael R. Maglio (Referencia 14 en la cita bibliográfica) sostiene que la sucursal más cercana de R1b es de Iberia y sus pequeños subclades que se encuentra en el oeste de Asia, Oriente Próximo y África son ejemplos de migración de regreso, y no de su origen. Este dato es bastante sorprendente por cuanto va en contra del sentido de la linea de migración de oriente a occidente.
http://www.nature.com/nature/journal/v522/n7555/full/nature14507.html (Referencias 6, 7)
http://biorxiv.org/content/early/2015/03/13/016477
http://originhunters.blogspot.pt/2014/08/iberian-r1b-y-dna-first-movers-in-europe.html
https://en.wikipedia.org/wiki/Haplogroup_R1b
La distribución Rb1 en Europa forma una banda de este a oeste, que es consistente como una entrada en Europa y procedente desde Asia de la difusión de la agricultura.
B. Arredi; ES Poloni; C. Tyler-Smith (2007). "El poblamiento de Europa". En Crawford, Michael H. genética antropológica: teoría, métodos y aplicaciones . Cambridge, Reino Unido: Cambridge University Press. pag. 394. ISBN 0-521-54697-4
https://en.wikipedia.org/wiki/Haplogroup_R1b
Esto fue comprobado por estudios posteriores que detectaron que los primeros subclades de Rb1 se encuentran en Asia Occidental y los más recientes en Europa occidental
B. Arredi; ES Poloni; C. Tyler-Smith (2007). "El poblamiento de Europa". En Crawford, Michael H. genética antropológica: teoría, métodos y aplicaciones . Cambridge, Reino Unido: Cambridge University Press. pag. 394. ISBN 0-521-54697-4
Myres, Natalie; Rootsi, Siiri; Lin, Alice A; Järve, Mari; King, Roy J; Kutuev, Ildus; Cabrera, Vicente M; Khusnutdinova, Elza K; et al. (2010). "Una de las principales cromosoma Y-haplogrupo R1b efecto Holoceno en Europa central y occidental" . European Journal of Human Genetics. 19 (1): 95-101. PMC 3.039.512  . PMID 20736979 . doi : 10.1038 / ejhg.2010.146
Cruciani; Trombetta, Beniamino; Antonelli, Cheyenne; Pascone, Roberto; VALESINI, Guido; Scalzi, Valentina; Vona, Giuseppe; Melegh, Bela; et al. (2010). "Fuerte diferenciación intra e inter-continental revelado por el cromosoma Y SNPs M269, U106 y U152". Forensic Science International: Genética . 5 (3): E49. PMID 20732840 . doi : 10.1016 / j.fsigen.2010.07.006
https://en.wikipedia.org/wiki/Haplogroup_R1b
Mientras que las estimaciones de edad en estos artículos son todas más recientes que el último máximo glacial (Aproximadamente hace 20.000 años), toda mención del neolítico, hace referencia a cuando la agricultura se introdujo en Europa desde le medio oriente. Neolítico es un candidato para ser el periodo en que esta migración se produjo. En términos generales, no hay concordancia entre los diversos investigadores acerca del tema, aunque en 2012, restos humanos del neolítico analizados para ADN-Y, dieron positivo para R1b
https://en.wikipedia.org/wiki/Haplogroup_R1bAmerican Journal of Physical Anthropology . 148 (4): 571-9. PMID 22552938 . doi : 10.1002 / ajpa.2207
http://onlinelibrary.wiley.com/doi/10.1002/ajpa.22074/abstract
. PMID 20736979 . doi : 10.1038 / ejhg.2010.146
Cruciani; Trombetta, Beniamino; Antonelli, Cheyenne; Pascone, Roberto; VALESINI, Guido; Scalzi, Valentina; Vona, Giuseppe; Melegh, Bela; et al. (2010). "Fuerte diferenciación intra e inter-continental revelado por el cromosoma Y SNPs M269, U106 y U152". Forensic Science International: Genética . 5 (3): E49. PMID 20732840 . doi : 10.1016 / j.fsigen.2010.07.006
https://en.wikipedia.org/wiki/Haplogroup_R1b
Mientras que las estimaciones de edad en estos artículos son todas más recientes que el último máximo glacial (Aproximadamente hace 20.000 años), toda mención del neolítico, hace referencia a cuando la agricultura se introdujo en Europa desde le medio oriente. Neolítico es un candidato para ser el periodo en que esta migración se produjo. En términos generales, no hay concordancia entre los diversos investigadores acerca del tema, aunque en 2012, restos humanos del neolítico analizados para ADN-Y, dieron positivo para R1b
https://en.wikipedia.org/wiki/Haplogroup_R1bAmerican Journal of Physical Anthropology . 148 (4): 571-9. PMID 22552938 . doi : 10.1002 / ajpa.2207
http://onlinelibrary.wiley.com/doi/10.1002/ajpa.22074/abstract
QUE DICEN OTROS INFORMES:

Figura 10. En el mapa se representan los haplogrupos del ADN del cromosoma Y a nivel mundial. Se nota información muy escasa en América del Sur y en Oceanía (Donde el informe de Family Tre DNA no informa nada). Si observamos el área de la península Ibérica, el % de frecuencia es bastante alto (Entre 60 y 100%). Recordemos que nuestros ancestros Messia, de acuerdo con la documentación existente, provienen de la región centro norte, del área de lo que hoy es Villacastin, Segovia, Comunidad autónoma de Castilla y León.
Las mayores frecuencias están en Europa donde R1 es predominante. R está muy extendido en el subcontinente Indio, Asia Central, Cáucaso, Cercano oriente y Xinjiang.
En los nativos americanos es el haplotipo más frecuente después de Q, especialmente en América del Norte en los Ojibwa (79%), Chipewayan (62%), Seminola (50%), Cheroqui (47%), Dogrib (40%) y Pápago (38%) y su presencia puede deberse a la colonización europea o tal vez esté relacionado con el poblamiento de América.
Pequeñas frecuencias se encuentran en Africa, Asia oriental, Siberia, Insulindia, Islas del Pacífico y nativos de Australia.
https://en.wikipedia.org/wiki/Haplogroup_R1b

Figura 11. De Maulucioni - Trabajo propio, CC BY-SA 3.0,
Europa
occidental
En la información remitida junto con los resultados de los análisis, hay un segundo mapa, más completo, en el cual se ve la ruta de migración del haplotipo Rb1, hasta la península ibérica. De allí debe haber pasado a Colombia (O a lo que era en ese entonces: la Nueva Granada) con los conquistadores españoles.
 |
| Figura 7. Mapa de migración de los haplotipos del cromosma Y, elaborado por Family Tree DNA. en la parte inferior derecha dice copyright 2006, es decir hace 11 años. No es claro porqué me remitieron con los resultados de los análisis, un mapa de migración tan simple como el que se muestra en la imagen anterior (Figura 6), la ruta ni siquiera termina en la península ibérica, desde donde vinieron nuestros genes a lo que hoy es Colombia. Igualmente, este (Figura 7) mapa fue elaborado hace 11 años, tiempo en el cual ha habido muchísima investigación en el tema y se ha ampliado bastante el cladograma. Creo que hay un afán financiero en esta compañía y una falta de seriedad en la emisión de sus resultados. |
Y es que de acuerdo con una publicación de la Sociedad internacional de Genealogía Genética (ISOGG) en 2016, cuando se toma una prueba estándar de ADN del cromosoma Y con compañías como Family Tree DNA, a usted le dan un haplogrupo base R1b1a2 (R-M269). Es entonces necesario análisis adicionales de SNP para confirmar a cual subclado de R1b usted pertenece. Dice la publicación que a veces es posible obtener un resultado predictivo a partir de una prueba de 67 marcadores STR-Y, Si la persona tiene concordancias (personas con resultados similares a una corta distancia genética), entonces se puede ordenar una prueba simple de ADN, de lo contrario hay que ordenar una prueba full de SNP
"When you take a standard Y-chromosome DNA test with
a company such as Family
Tree DNA you
will be given a base haplogroup assignment such as R1b1a2 (R-M269). It is
necessary to order additional SNP testing
to confirm which subclade of
R1b you belong to. It is sometimes possible to predict the R1b subclade from a
67-marker Y-STR haplotype.
If the participant has close matches at 67 markers the prediction can sometimes
be informed by the SNP status of his matches. If the subclade can be predicted
with reasonable confidence then single SNP testing can be ordered from Family
Tree DNA's à la carte SNP menu. Otherwise it is necessary to order a full SNP test for
confirmation of your SNP status. SNP status can also be confirmed with the 23andMe test
though this incorporates a much smaller range of Y-SNPs and will not provide
such a detailed haplogroup assignment."
ORIGEN Y DISPERSION DEL HAPLOGRUPO Rb1
R1b es un subclado dentro de la "macro-haplogrupo" "Haplogrupo" K (K-M9), que es una de las agrupaciones predominantes de todo el resto de líneas masculinas humanos fuera de África. K se cree que se originó en Asia (como es el caso con un haplogrupo incluso antes ancestral, F, (F-M89). en un "rápido proceso de diversificación de K-M256 probablemente ocurrió en el sudeste de Asia, con expansiones hacia el oeste posteriores de los ancestros de haplogrupos R y Q ".
https://en.wikipedia.org/wiki/Haplogroup_R1b (Referncia 2)
https://en.wikipedia.org/wiki/Haplogroup_R1b
QUÉ DICEN LOS RESULTADOS (Emitidos por Family Tree DNA)
 |
| Figura 8. De acuerdo con el informe remitido al suscrito por Family Tree DNA (Gene by GeneLtd.) el haplogrupo RM269 se encuentra en: Europa, norte de Africa, Medio Oriente, sur de Asia, Asia central y norte de Asia. No enviaron reportes de frecuencia en América y parece, de acuerdo con las figuras de frecuencia, no hay R-M269 en el pacífico sur ni en el centro-sur de Africa. |
 |
| Figura 9. A partir del mapa de frecuencias remitido por Family Tree DNA (Gene by Gene Ltd.) las siguientes son las frecuencias del haplogrupo R-M269 en las seis regiones del mundo donde se reporta: Europa: 45.43%; norte de Africa: 6.11%; Medio Oriente: 20.56%; norte de Asia: 7.66%; sur de Asia: 40.51%; Asia central: 31.44% |
El punto de origen de R1b se cree que está en Eurasia, muy probablemente en Asia Occidental T. Karafet et al. (2008, ver referencia 7 en la cita bibliográfica) estimaron la edad de R1, el padre de R1b, como 18.500 años antes del presente.
Las primeras investigaciones sobre los orígenes de R1b se centraron en Europa. En 2000, Ornella Semino y sus colegas (ver referencia 8 en la cita bibliográfica) argumentaron que R1b había estado en Europa antes del final de la edad de hielo, y se había extendido hacia el norte desde un refugio Ibérica después del último glacial (Ocurrió hace unos 20.000 años). Las estimaciones de edad de R1b en Europa han disminuido de manera constante en los estudios más recientes, al menos en relación con la mayoría de R1b, con estudios más recientes que sugieren una edad neolítica o menos. (ver referencias 6, 9, 10, 11 en la cita bibliográfica) Por otro lado, Morelli et al. recientemente (en 2010, referencia 12) han intentado defender un origen paleolítico de R1b1b2.
http://www.nature.com/nature/journal/v522/n7555/full/nature14507.html (Referencias 6, 7)
http://biorxiv.org/content/early/2015/03/13/016477
http://originhunters.blogspot.pt/2014/08/iberian-r1b-y-dna-first-movers-in-europe.html
https://en.wikipedia.org/wiki/Haplogroup_R1b
La distribución Rb1 en Europa forma una banda de este a oeste, que es consistente como una entrada en Europa y procedente desde Asia de la difusión de la agricultura.
B. Arredi; ES Poloni; C. Tyler-Smith (2007). "El poblamiento de Europa". En Crawford, Michael H. genética antropológica: teoría, métodos y aplicaciones . Cambridge, Reino Unido: Cambridge University Press. pag. 394. ISBN 0-521-54697-4
https://en.wikipedia.org/wiki/Haplogroup_R1b
Esto fue comprobado por estudios posteriores que detectaron que los primeros subclades de Rb1 se encuentran en Asia Occidental y los más recientes en Europa occidental
B. Arredi; ES Poloni; C. Tyler-Smith (2007). "El poblamiento de Europa". En Crawford, Michael H. genética antropológica: teoría, métodos y aplicaciones . Cambridge, Reino Unido: Cambridge University Press. pag. 394. ISBN 0-521-54697-4
Myres, Natalie; Rootsi, Siiri; Lin, Alice A; Järve, Mari; King, Roy J; Kutuev, Ildus; Cabrera, Vicente M; Khusnutdinova, Elza K; et al. (2010). "Una de las principales cromosoma Y-haplogrupo R1b efecto Holoceno en Europa central y occidental" . European Journal of Human Genetics. 19 (1): 95-101. PMC 3.039.512 . PMID 20736979 . doi : 10.1038 / ejhg.2010.146
Cruciani; Trombetta, Beniamino; Antonelli, Cheyenne; Pascone, Roberto; VALESINI, Guido; Scalzi, Valentina; Vona, Giuseppe; Melegh, Bela; et al. (2010). "Fuerte diferenciación intra e inter-continental revelado por el cromosoma Y SNPs M269, U106 y U152". Forensic Science International: Genética . 5 (3): E49. PMID 20732840 . doi : 10.1016 / j.fsigen.2010.07.006
https://en.wikipedia.org/wiki/Haplogroup_R1b
Mientras que las estimaciones de edad en estos artículos son todas más recientes que el último máximo glacial (Aproximadamente hace 20.000 años), toda mención del neolítico, hace referencia a cuando la agricultura se introdujo en Europa desde le medio oriente. Neolítico es un candidato para ser el periodo en que esta migración se produjo. En términos generales, no hay concordancia entre los diversos investigadores acerca del tema, aunque en 2012, restos humanos del neolítico analizados para ADN-Y, dieron positivo para R1b
https://en.wikipedia.org/wiki/Haplogroup_R1bAmerican Journal of Physical Anthropology . 148 (4): 571-9. PMID 22552938 . doi : 10.1002 / ajpa.2207
http://onlinelibrary.wiley.com/doi/10.1002/ajpa.22074/abstract
QUE DICEN OTROS INFORMES:
 |
Figura 10. En el mapa se representan los haplogrupos del ADN del cromosoma Y a nivel mundial. Se nota información muy escasa en América del Sur y en Oceanía (Donde el informe de Family Tre DNA no informa nada). Si observamos el área de la península Ibérica, el % de frecuencia es bastante alto (Entre 60 y 100%). Recordemos que nuestros ancestros Messia, de acuerdo con la documentación existente, provienen de la región centro norte, del área de lo que hoy es Villacastin, Segovia, Comunidad autónoma de Castilla y León.
|
Las mayores frecuencias están en Europa donde R1 es predominante. R está muy extendido en el subcontinente Indio, Asia Central, Cáucaso, Cercano oriente y Xinjiang.
En los nativos americanos es el haplotipo más frecuente después de Q, especialmente en América del Norte en los Ojibwa (79%), Chipewayan (62%), Seminola (50%), Cheroqui (47%), Dogrib (40%) y Pápago (38%) y su presencia puede deberse a la colonización europea o tal vez esté relacionado con el poblamiento de América.
Pequeñas frecuencias se encuentran en Africa, Asia oriental, Siberia, Insulindia, Islas del Pacífico y nativos de Australia.
https://en.wikipedia.org/wiki/Haplogroup_R1b
 |
Figura 11. De Maulucioni - Trabajo propio, CC BY-SA 3.0,
|
Las frecuencias más altas se encuentran en poblaciones de Europa Atlántica, principalmente en los vascos (87%) y galeses (89%), seguidamente en los irlandeses (81%), escoseses (77%), españoles (72%), ingleses (60%), belgas (63%) y portugueses del sur (50%9). Encontramos menos frecuencia en los italianos (Italia continental: 40%), alemanes (39%), checos (35,6%), sicilianos (24.5%); noruegos (25,9%), suecos (20%), sardos (10%) y croatas (15.7%)
https://en.wikipedia.org/wiki/Haplogroup_R1b (Referencias 13, 14, 15, 16, 17, 18, 19, 20, 21)
Uno de los más altos niveles de R1b se encuentra entre los vascos, que hablan una lengua no indoeuropea; lo que contradice una fuente exclusiva o predominantemente Indo-Europea.
Una de las hipótesis sobre el caso de los vascos es que un pueblo de habla indoeuropea invadió y conquistó el País Vasco, y luego, después de haber traído ninguna o pocas mujeres con ellos, se casaron con mujeres locales, posiblemente de una sociedad matrilineal. Entonces, las mujeres pueden haber sido responsables de que los niños que resultaran hablando su propia lengua y con sus prácticas culturales, en lugar de las de los padres (varones). Esta posible explicación se refiere además a tal punto que mientras que otras regiones de alta R1b en Europa Occidental (tales como las Islas Británicas y el sur de Alemania) muestran desproporcionadamente altas incidencias de haplogrupos de ADNmt que corresponden a un origen en las estepas de origen póntico (específicamente ADNmt haplogrupos I, U2, U3 , U4, y W), el País Vasco no las tiene. De hecho, la región vasca no muestra prácticamente ningún ADN mitocondrial que pueda estar relacionado con el ADN que existe en las estepas de origen póntico.
eupedia.com/genetics
https://en.wikipedia.org/wiki/Haplogroup_R1b
Una de las hipótesis sobre el caso de los vascos es que un pueblo de habla indoeuropea invadió y conquistó el País Vasco, y luego, después de haber traído ninguna o pocas mujeres con ellos, se casaron con mujeres locales, posiblemente de una sociedad matrilineal. Entonces, las mujeres pueden haber sido responsables de que los niños que resultaran hablando su propia lengua y con sus prácticas culturales, en lugar de las de los padres (varones). Esta posible explicación se refiere además a tal punto que mientras que otras regiones de alta R1b en Europa Occidental (tales como las Islas Británicas y el sur de Alemania) muestran desproporcionadamente altas incidencias de haplogrupos de ADNmt que corresponden a un origen en las estepas de origen póntico (específicamente ADNmt haplogrupos I, U2, U3 , U4, y W), el País Vasco no las tiene. De hecho, la región vasca no muestra prácticamente ningún ADN mitocondrial que pueda estar relacionado con el ADN que existe en las estepas de origen póntico.
eupedia.com/genetics
https://en.wikipedia.org/wiki/Haplogroup_R1b
Particularmente en España se encontró en menor porcentaje en Galicia (58%) y Andalucía occidental (55%), mientras que en Andalucía oriental y el centro de España, Castilla-La mancha, alcanzaban un 72%, los porcentajes más elevados junto con Cataluña y el País Vasco y cerca de los niveles de R1b más altos de Europa por encima del 80% obtenidos en Gales, Irlanda y Bretaña francesa.
https://en.wikipedia.org/wiki/Haplogroup_R1b (Referencias 22, 23)
Hay que recordar que lo que se tiene de acuerdo con documentos, es que nuestro cromosma Y viene de Segovia (Villacastin) en la comunidad autónoma de Castilla y León, en la parte norte de la meseta de la península Ibérica, área con grandes porcentajes de prevalencia de Rb1 en todos los estudios.
Europa oriental y el Cáucaso
Encontramos en eslovacos: 35,6%; polacos: 11.6% a 16.4%; letones: 15%; húngaros: 13.3%; griegos 13.5% a 22.8%; albanos: 17.6%; rumanos: 13%; eslovenos: 21%; búlgaros: 17%; serbios: 10.6%; rusos: 2.8% a 21.3%
En el Cáucaso se presentan 43% en osetios y 32.4% en armenios.
https://en.wikipedia.org/wiki/Haplogroup_R1b (Referencias 13, 14, 21, 24, 25, 26, 27, 28)
Asia
En Asia encontramos 37% en turcomanos, 40% en la zona sur del mar muerto (Jordania) y 8% en general en Jordania. 16.3% en Turquia, 11.3% en Irak, 11.2% en kurdos, 10% en judios Askenazi, 9.9% en sirios, 9.8% uzbekos (Referencia de Spencer Wells en 2001), 18% en uzbekos de Afganistán, 7.4% en Pakistán.
Hay que recordar que lo que se tiene de acuerdo con documentos, es que nuestro cromosma Y viene de Segovia (Villacastin) en la comunidad autónoma de Castilla y León, en la parte norte de la meseta de la península Ibérica, área con grandes porcentajes de prevalencia de Rb1 en todos los estudios.
Europa oriental y el Cáucaso
Encontramos en eslovacos: 35,6%; polacos: 11.6% a 16.4%; letones: 15%; húngaros: 13.3%; griegos 13.5% a 22.8%; albanos: 17.6%; rumanos: 13%; eslovenos: 21%; búlgaros: 17%; serbios: 10.6%; rusos: 2.8% a 21.3%
En el Cáucaso se presentan 43% en osetios y 32.4% en armenios.
https://en.wikipedia.org/wiki/Haplogroup_R1b (Referencias 13, 14, 21, 24, 25, 26, 27, 28)
Asia
En Asia encontramos 37% en turcomanos, 40% en la zona sur del mar muerto (Jordania) y 8% en general en Jordania. 16.3% en Turquia, 11.3% en Irak, 11.2% en kurdos, 10% en judios Askenazi, 9.9% en sirios, 9.8% uzbekos (Referencia de Spencer Wells en 2001), 18% en uzbekos de Afganistán, 7.4% en Pakistán.
https://en.wikipedia.org/wiki/Haplogroup_R1b 8Refeencias 31, 32, 33, 34, 35, 35, 37)
Africa
En el noreste de Africa hay una frecuencia del 40% en los hausas de Sudan y en general en Sudán 10%. En el noroeste hay 10.8% en Argelia.
Se presenta en alta frecuencia en el norte de Camerún (60.7 a 94.7%), especialmente en los uldeme. Se encontró 3% en os fante de Ghana, 9% en los bassa del sur de Camerún, 5% en los herero de Namibia, 4% en los ambo de Namibia y 4% en Egipto y Tunez.
https://en.wikipedia.org/wiki/Haplogroup_R1b (Refeencias 38, , 39, 40, 41, 42, 43)
América
En nativos americanos es común, especialmente en los pueblos algonquinos de Norteamérica y no se ha demostrado aún si su origen tiene relación con el mestizo europeo o debido a migraciones siberianas. Su presencia se identificó primero como P(M445) pero se refiere en realidad al hoplogrupo R1b-P25 y el enigma de su origen se puede revelar luego de un estudio de subclados. Esto no lo mencionan los informes remitidos por Family Tree DNA.
Siberia
Se ha encontrado el subclado R1b-M73 en bajas frecuencias en pueblos túrquicos en el sur de Siberia.
https://en.wikipedia.org/wiki/Haplogroup_R1b
https://es.wikipedia.org/wiki/Haplogrupo_R1b_del_cromosoma_Y
https://es.wikipedia.org/wiki/Haplogrupo_R1b_del_cromosoma_Y
Rb1 es un subclado o subgrupo del macrogrupo K (K-M9), que es una de las agrupaciones predominantes del todo el resto de lineas masculinas de humanos fuera de Africa. K se cree que se originó en Asia, probablemente el el sudeste de Asia con expansiones al sudeste de Asia, son los ancestros de los grupos posteriores R y Q. https://en.wikipedia.org/wiki/Haplogroup_R1b
Rb1 es un subclado o subgrupo del macrogrupo K (K-M9), que es una de las agrupaciones predominantes del todo el resto de lineas masculinas de humanos fuera de Africa. K se cree que se originó en Asia, probablemente el el sudeste de Asia con expansiones al sudeste de Asia, son los ancestros de los grupos posteriores R y Q. https://en.wikipedia.org/wiki/Haplogroup_R1b
Lo raro del tema es que casi no hay o mejor dicho no hay información que hable sobre la frecuencia del haplogrupo en suramérica, específicamente en Colombia; si la conquista Española fue hacia el año 1500, es decir hace 5 siglos, ya debería haber información sobre suramérica y debería haber datos sobre Colombia specíficamente.
Otras personas cuyos resultados coinciden total o parcialmente con quien contrata la prueba, pueden ser vistos de dos maneras con múltiples variables. En los resultados parece una sección que se llama Y-DNA partidos. Los "partidos" son las personas que se han hecho la prueba y que tienen coincidencias en su haplotipo o parte de él con el mío en este caso. Esto es lo que muestra la tabla (Figura 12) de acuerdo con lo que uno le programa en las casillas que aparecen en la parte superior de la misma. En mi caso se pueden ver en esta casilla: la base de datos completa o solo las coincidencias que escogí de acuerdo con el apellido o con asociaciones que trabajan investigando el apellido (España/casa, Mejia, Nueva España o Las Migraciones mundiales sefardíes).

Figura 12 El número de marcadores comprometidos en la búsqueda se puede seleccionar (12, 25,37, 67) según la prueba que uno haya comprado. Por ejemplo, yo compré la prueba Y-67, hasta ese número de marcadores puedo investigar. En la búsqueda se puede igualmente colocar la distancia genética, partiendo desde 0 que quiere decir la coincidencia total y a partir de allí, varias distancias catalogadas por pasos, hasta 7 que es el máximo. También se puede involucrar el apellido en la búsqueda,
De esta forma, el total de resultados depende de cuáles variables involucramos y del número total de marcadores; si coloco 12 marcadores, los resultados pueden ser del orden de miles, porque 12 es la prueba a la que más acceden los usuarios; de ahí en adelante el número de resultados se va reduciendo hasta llegar a 111 que es el kit con más alto número de marcadores a investigar. En la tabla coloqué: base de datos completa, 25 marcadores, 25 resultados por página y me arrojó 2 resultados. A medida que colocaba menos marcadores aparecían más coincidencias.
Otra forma de ver las coincidencias es con un mapa. Al comienzo del informe hay una barra que dice "matches maps" que la traducen como "mapas partidos" (Mapas de coincidencias).
Picando encima de la barra "matches maps" o "Mapas partidos". En la parte superior izquierda del recuadro hay una barra en la que se pueden seleccionar el número de marcadores. Picando encima, aparecen solo dos coincidencias.

Figura 13 Si disminuyo el número de coincidencias, parece un mayor número de resultados (Figura 14). Al contrario, si coloco muchas coincidencias (Figura13), disminuye el número de resultados encontrados. Cada uno de los globitos que hay en el mapa es un resultado o persona con la cual mis datos del análisis del ADN-Y coinciden total o parcialmente.
Este es el mapa cuando seleccioné 12 marcadores:

Figura 14. Si uno pica encima de uno de los globitos, aparecen los datos de la persona a la cual corresponde el globito o seña en el mapa. Me llamó la atención que con 12 marcadores, tenía 2 coincidencia en Suecia.

m
Figura 15. Al picar encia del globito de la parte superior, apareció la siguiente información (Figura 16):

Figura 16. En la parte de abajo de esta ficha de datos hay un recuadro que dice "Tip calculator comparación". Picando encima de este recuadro apareció una tabla que compara mis datos con los Delia persona con la cual coinciden: observemos la tabla (Figura 17):
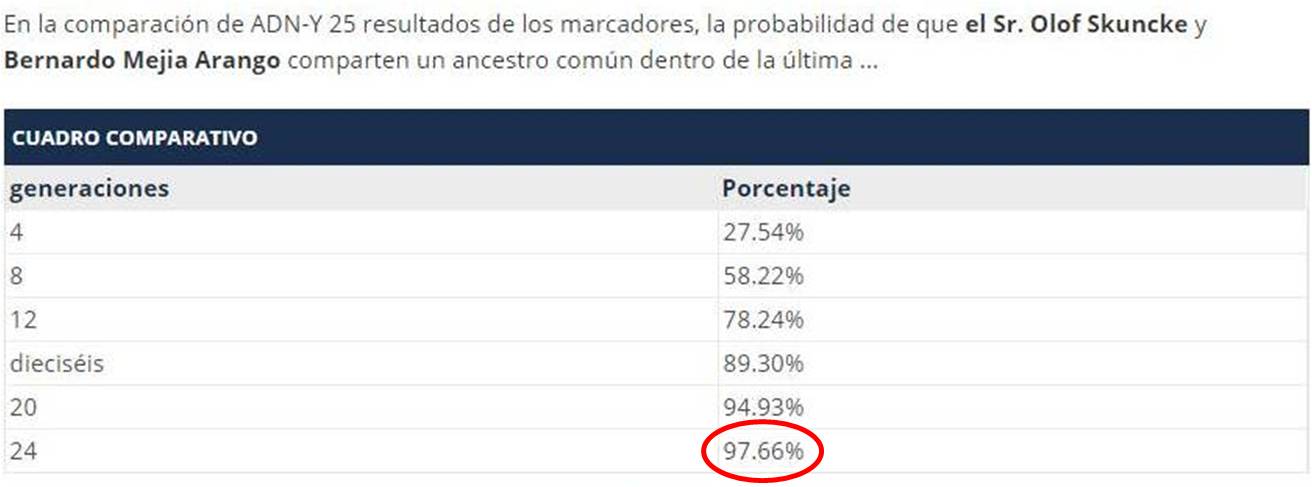
Figura 17. La información que aparece tiene dos columnas, la de la izquierda es el número de generaciones en forma progresiva hacia atrás en el tiempo y la columna de la derecha es la probabilidad de que esta persona y yo tengamos un ancestro común. Es de notar que a medida que aumenta el número de generaciones, la probabilidad de que Olof Skuncke y yo, Bernardo Mejía Arango, tengamos un ancestro común es mayor. De acuerdo con la tabla, este señor y yo, 24 generaciones hacia arriba, tenemos la probabilidad del 97.66% de que tengamos un ancestro común. Es decir somos descendientes de un ancestro común que vivió 24 generaciones hacia atrás en nuestro árbol.
En el mapa de coincidencias (Figura 18), encontré una persona en Colombia, usando 37 marcadores

Figura 18. Picando encima el globito, apareció el "dueño" de la muestra que tiene coincidencias con la mía en términos de ADN del cromosma Y.

Figura 19. Y picando encima del recuadro "Tip calculator comparación", apareció la siguiente tabla:

Figura 20. Es decir, el señor Cesar Mejía y yo, tenemos una probabilidad del 99.98% de que 24 generaciones hacia atrás, tengamos un ancestro común. Este ancestro común puede haber vivido en península Ibérica (Actual España) diez generaciones antes de que nuestros ancestros Mejia (Messia) vinieran al Nuevo Reino de granada (La Colombia de aquel entonces) hace 14 generaciones, un poco más de 400 años.
El informe remitido por la compañía Familytree DNA tiene una sección que se llama "Mapa de SNP", que es un cladograma en el que aparece hasta donde está tipificado nuestro marcador de ADN del cromosma Y que nos identifica, en mi caso R-M269.

Figura 21. En este cuadro que corresponde a un cladograma, mi haplogrupo R-M269 está colocado sobre una linea de color verde claro, de allí hacia abajo están todas las ramificaciones que conducen a identificar cada uno de los polimorfismos de nucleótido simple (SNPs) disponibles en las pruebas, esto se ve a la derecha de la tabla, en unos cajoncitos o cuadritos azules. Si uno pica encima de cada SNP, está solicitando y aceptando la prueba, igualmente la parte inferior parece un letrero que dice SNP Total: $0.00. es aquí donde va sumando el costo de lo que uno selecciona y por lo que debe pagar si quiere que le sigan tipificando su cladograma en términos de SNPs.
El informe incluye un mapa de los SNPs del ADN-Y (Polimorfismos de nucleótido simple del ADN del cromosoma Y) que ya están esblecido. Busqué los del haplogrupo R y seleccioné un grupo de 6 (Que es el máximo permitido). El programa detectó de estos 6, el R-100 y me mostró el siguiente mapa:

Figura 22. Las áreas en rojo correponden al tamaño del clúster en territorio (En unidades de mil metros de diámetro, aunque da la posibilidad de hacerlo en kilómetros) donde están los individuos cuyo SNP R-100 coincide con el mío en el ADN del cromosma Y.



















Es un apellido de origen judio-sefardí, asentado en el norte de España (Asturias y Galicia). Tras la Reconquista de España, se extendió en Castilla y Extremadura. A partir de la expulsión de los judíos por los Reyes Católicos, en 1492, pasó a Europa, Marruecos y América.
ResponderEliminar